

วันพฤหัสบดีที่ 20 มีนาคม 2568 เวลา 23:15 น. ตามเวลาในประเทศไทย คุณรัตนพล วงศ์นภาจันทร์ (คุณซัน) ประธานกรรมการฝ่ายบริหาร และผู้ก่อตั้ง Siam.AI Cloud ได้รับเกียรติร่วมงาน NVIDIA GTC 2025 ที่เมืองซานโฮเซ่ รัฐแคลิฟอร์เนีย ประเทศสหรัฐอเมริกา พร้อมกันนี้ยังได้รับเกียรติขึ้นกล่าวในเซสชั่น Sovereign AI Summit หัวข้อ “Empower the Ecosystem with Sovereign Foundation Models” งานนี้ถือได้ว่า เป็นการทำหน้าที่ตัวแทนประเทศไทยในการนำเสนอการพัฒนาเอไอของบ้านเรา บนเวทีสากลระดับโลกด้านเอไอ สำหรับคีย์ไฮไลท์ประกอบไปด้วย
“ประเทศไทยจะกลายเป็นศูนย์กลางด้านเอไอ ในภูมิภาคเอเชียตะวันออกเฉียงใต้”
เหตุผลหลักก็คือ เรามีพลังงานไฟฟ้าที่เพียงพอ เรามีทรัพยากรน้ำที่อุดมสมบูรณ์และในปัจจุบันเราก็มี ศูนย์ข้อมูล (Data Center) จำนวนมากภายในประเทศ นอกจากนี้ นโยบายภาครัฐยังให้การสนับสนุน ซึ่งเราหวังว่า Sovereign AI และกรณีการใช้งานในระดับประเทศ จะเติบโตในอนาคต
“กุญแจสู่ความสำเร็จของ Sovereign AI”
คุณซันได้พูดถึงปัจจัยสู่ความสำเร็จว่า เรา (ประเทศไทย), ต้องมี AI Factory ซึ่งเป็นจุดเริ่มต้น, ต้องมีข้อมูล (หมายถึงข้อมูลที่เป็นภาษาไทยเพื่อสร้างโมเดล), ต้องมีโมเดล AI เป็นของเราเอง, ต้องมีบุคลากรที่พร้อมมีความรู้ความสามารถด้าน AI และสุดท้ายต้องมีระบบนิเวศ AI ที่ดีด้วย
“ผมไม่ได้ต้องการที่จะแข่งขันกับโมเดลเหล่านั้น แค่อยากจะทำให้มันเป็นโมเดลที่ดีที่สุดสำหรับลูก ๆ ของผม”
คุณซันได้กล่าวถึงเหตุผลที่สำคัญของ Sovereign AI ว่า
ในประเทศของผม มากกว่า 70% ของคน Gen Z “พวกเขาเหล่านั้นอาจจะไม่ฟังหัวหน้าของพวกเขาอีกต่อไป เพราะพวกเขาเชื่อว่า ChatGPT นั้นถูกต้องมากกว่า” แม้แต่กับลูก ๆ ของผม พวกคุณรู้ไหม เขาเถียงกับผมว่า
“พ่อครับ พ่อผิด”
ผมถามว่า “แล้วทำไมถึงรู้ว่าพ่อผิด?”
ลูกก็ตอบว่า “ถาม ChatGPT”
ซึ่งผมคิดว่า มันก็ไม่ได้ผิดอะไร และมันก็เป็นโมเดลที่ดีมาก ๆ แต่มันก็ทำให้ผมกังวลนิดหน่อย ในเมื่อคุณไม่ได้มีโมเดลที่รู้จักประเทศของคุณ หรือรู้จักตัวตนของคุณ หรือใครที่สร้างคุณขึ้นมา คุณเป็นอย่างไร ผมเชื่อว่าหากคุณได้เคยทำโมเดลภาษาใหญ่ ๆ คุณจะเห็นว่า บางครั้งมันก็ไม่ถูกต้องเสมอไป ใช่ไหมครับ?
ทุกคนที่อยู่ที่นี่ พวกคุณต่างก็มี อาหารของตัวเองใช่ไหม? มีวัฒนธรรมของตัวเอง
ถ้ามี ส่วนผสมบางอย่างขาดหายไป มันก็จะไม่ใช่ของแท้สำหรับเรา ใช่ไหมครับ?
นี่คือเหตุผลที่เราทำเพื่อประเทศไทย ซึ่งแน่นอนว่าตอนนี้เรากำลังทำอยู่ ที่เราต้องการเน้นคือวัฒนธรรมของเราเอง มีหลาย ๆ คนมักจะถามผมว่า ทำไมผมถึงต้องการสร้างโมเดลเอง “ผมไม่ได้ต้องการที่จะแข่งขันกับโมเดลเหล่านั้น แค่อยากจะทำให้มันเป็นโมเดลที่ดีที่สุดสำหรับลูก ๆ ของผม” ดังนั้น นี่คือหนึ่งในด้านที่เรามุ่งเน้นไม่ว่าจะเป็น การท่องเที่ยว อาหารไทย วัฒนธรรมไทย และทางการแพทย์
เราจะให้การสนับสนุน ห้องปฏิบัติการวิจัย มหาวิทยาลัย และ งานวิจัยด้าน AI ผ่าน ระบบประมวลผลประสิทธิภาพสูงของเรา รัฐบาลของเราต้องการมุ่งเน้นไปที่ Medical AI เป็นหลัก ทั้งในประเทศไทย และเอเชียตะวันออกเฉียงใต้ ในความเป็นจริง เราเป็นศูนย์กลางของการแพทย์แผนปัจจุบันอยู่แล้ว เนื่องจากเรามีแพทย์ และสถานพยาบาลเป็นจำนวนมาก ดังนั้นเราจึงต้องพัฒนาอุตสาหกรรม Medical AI

เราจึงร่วมมือกับมหาวิทยาลัยมหิดล ภายใต้มหาวิทยาลัยมหิดลก็มีโรงพยาบาลรัฐบาลหลายแห่ง อย่างโรงพยาบาลศิริราชโรงพยาบาลรามาธิบดี โรงพยาบาลเหล่านี้ก็มีข้อมูลที่จำเป็นเกี่ยวกับการแพทย์ของคนไทย เราสามารถนำข้อมูลเหล่านั้นมาพัฒนาโมเดล AI ได้ และแน่นอนว่าเราไม่สามารถทำสิ่งนี้ได้เพียงลำพัง วันนี้ผมภูมิใจมากที่ได้ประกาศการร่วมทุนกับ Eternis ซึ่งเป็นสตาร์ทอัพด้าน AI ที่ซานฟรานซิสโก พวกเขาจะช่วยเราสร้างโมเดล AI ซึ่งจะทำให้เราสามารถที่จะเปิดตัวโมเดลเฉพาะทาง ได้ประมาณ 5-10 โมเดลต่อปี
“ในอนาคต พวกเขาอาจสามารถเพิ่ม IQ ให้กับคนได้”
สำหรับ Eternis ก็เป็นพันธมิตรกับ Primamente เช่นกัน Primamente เป็นบริษัทวิจัยชีวการแพทย์ ที่มุ่งเน้น การค้นคว้ายา สำหรับ อัลไซเมอร์และมะเร็ง ซึ่งผมได้มีโอกาสพูดคุยกับ CEO ของเขาเมื่อวันก่อน เขาบอกว่าในอนาคต พวกเขาอาจสามารถเพิ่ม IQ ให้กับคนได้ แล้วคุณลองถามตัวเองดู ว่าคุณจะอยากทำมันไหม? คุณอยากจะให้ตัวเองหรือให้ลูกของคุณมี IQ เพิ่มขึ้นหรือเปล่า? นี่เป็นคำถามที่น่าสนใจนะครับ

อีกสิ่งหนึ่งที่เราอยากทำร่วมกับมหาวิทยาลัยทั้งหมดโดยเฉพาะมหาวิทยาลัยที่เกี่ยวข้องกับ AI แน่นอนว่ามี มหาวิทยาลัย CMKL อยู่ด้วย เราได้ทำการก่อตั้งสถาบันวิศวกรรม AI ที่รวมหลาย ๆ มหาวิทยาลัยที่เกี่ยวข้องกับ AI แต่ปัญหาก็คือมหาวิทยาลัยแต่ละแห่ง ต่างก็มีงบประมาณของตัวเองในการทำ AI Cloud แต่ละที่มีงบประมาณที่แตกต่างกัน และแต่ละที่ก็ต้องการมีเซิร์ฟเวอร์เป็นของตัวเอง และนั่นเป็นปัญหาที่แก้ไขได้ยากมาก ดังนั้นด้วยแนวคิดของความร่วมมือ เราจึงเชิญพวกเขามารวมตัวกัน และเราจะสร้างคลาวด์ประมวลผลขนาดใหญ่เพื่อให้มหาวิทยาลัยทั้งหมดสามารถแชร์ทรัพยากรร่วมกัน

แน่นอนว่า เราจะก้าวไปข้างหน้าไม่ได้หากขาด บุคลากรที่พร้อมสำหรับ AI ดังนั้น ผมจึงจัดงานที่มีชื่อว่า “AI for Youth” สำหรับเยาวชน ในงานนี้ เรานำเสนออุปกรณ์ OEMs ทั้งหมดของเรา รวมถึง อุปกรณ์ต่างๆ ที่ใช้ในงานด้าน AI เพื่อให้เด็กๆ สนใจและมีแรงบันดาลใจมากขึ้น และเราก็มีเทศกาลดนตรีปิดท้ายงานด้วย! ขอขอบคุณทาง NVIDIA ที่ให้การสนับสนุนเราในเรื่องนี้ นอกจากนี้เรายังมี บูธแคมป์ เพื่อสอนเกี่ยวกับ LLM ของเรา และเรายังมอบ รางวัล ให้กับผู้ที่เข้าร่วมด้วย ทุกครั้งที่เราจัด บูธแคมป์ จำนวนผู้เข้าร่วมจะ เพิ่มขึ้น ทุกครั้ง

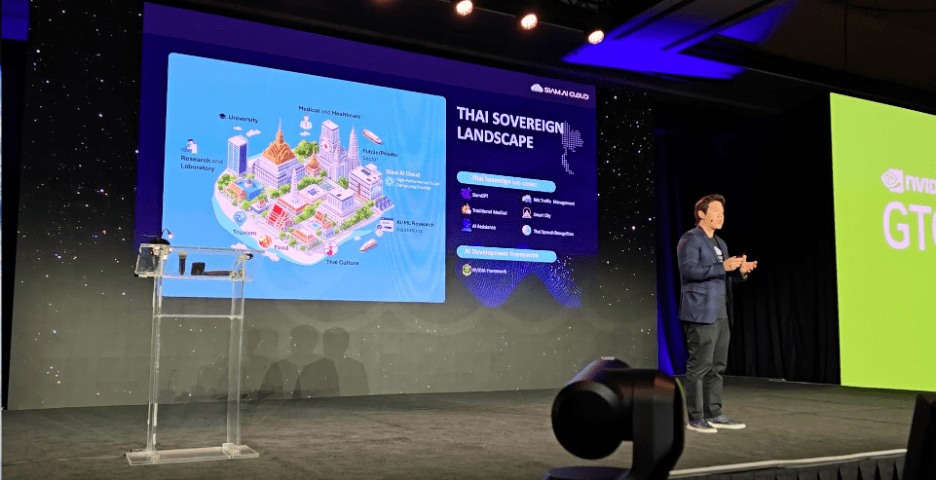
“LLM ของเรามีชื่อว่า SiamGPT“
ตอนนี้เรามาถึงหัวข้อเกี่ยวกับ LLM สำหรับประเทศไทย LLM ของเรามีชื่อว่า SiamGPT ซึ่งจะเป็นโมเดลพื้นฐานของเราในการพัฒนาร่วมกับรัฐบาลไทย ร่วมกับสถาบันไทย ห้องปฏิบัติการวิจัยของไทย และเราจะเปิดเป็นโอเพ่นซอร์ส ครับ และนี่คือฟังก์ชันหลักที่เราได้พัฒนาไว้ เพราะประเทศไทยเรารู้จักกันดีในเรื่อง การท่องเที่ยว เราจึงมี SiamGPT Tourism ซึ่งสามารถให้ข้อมูลเชิงลึกเกี่ยวกับการเดินทาง เช่น ควรไปที่ไหน เวลาทำการของสถานที่ต่าง ๆ รวมถึงร้านอาหารท้องถิ่นที่นักท่องเที่ยวทั่วไปไม่ค่อยรู้จัก ซึ่งเป็นข้อมูลที่เราต้องการนำเสนอ

เรายังมี SiamGPT Sweetheart สำหรับบางคนที่รู้สึก เหงา คุณสามารถพูดคุยกับมันได้นะครับ
SiamGPT Medical ประเทศไทยยังมีชื่อเสียงในเรื่อง การแพทย์แผนไทย ดังนั้นเราจึงนำข้อมูลเกี่ยวกับ การแพทย์แผนไทย มาผนวกกับ SiamGPT ของเรา และสุดท้าย แต่ไม่ท้ายสุด เพราะเรามี SiamGPT StudentLoanโครงการกู้ยืมเงินเพื่อการศึกษา ซึ่ง มหาวิทยาลัย หลายแห่งมักมีคำถามที่ไม่สามารถตอบได้จาก นักศึกษาหลายหมื่นคน ในเวลาเดียวกัน ดังนั้นเราจึงนำข้อมูลนี้เข้าไปใน LLM ของเราเช่นกันครับ นอกจากนี้เรายังทำ text to image และ text to video แต่ในเวอร์ชันนี้เป็น อวาตาร์ ซึ่งเรายังมี text to image ในเวอร์ชันที่เป็น ภาพจริง ด้วย
เหตุผลที่เราต้องทำก็เพราะว่า เมื่อเราทดสอบโมเดล จาก โอเพ่นซอร์ส บางครั้ง เมื่อคุณขอให้แสดงภาพ หญิงสาวไทย ที่ใส่ ชุดไทยดั้งเดิม แม้ว่าโมเดลจะสร้างออกมาเป็น หญิงสาวเอเชีย แต่คุณและผมรู้ดีว่า ใบหน้า มันไม่ใช่ หมายถึงว่าเรารู้ว่ามันไม่ใช่หน้าตาของคนไทย นี่คือเหตุผลที่เราต้องพัฒนาโมเดลของเราเอง

ผมไม่แน่ใจว่าหลายๆ คนที่นี่ เคยมีประสบการณ์ในการสร้าง โมเดล AI LLM มากน้อยเพียงใด แต่สิ่งที่เราประสบมาคือ ภาษาไทย ผมจะบอกว่า จำนวนประชากรของเรา ไม่ค่อยใหญ่ ดังนั้นข้อมูลที่มีเกี่ยวกับ ภาษาไทย อาจจะไม่เพียงพอ สำหรับโมเดลโอเพ่นซอร์ส นี่คือสิ่งที่เกิดขึ้นครับ บางครั้งมันจะ เกิดการ hallucinate (หลอน) โดยมีภาษาอื่นๆ แทรกออกมาเสมอ เราทำการทดสอบโดยตั้งคำถามประมาณ 300 ข้อ และพบว่ามีข้อผิดพลาดเกิดขึ้นประมาณ 30% เราพยายามค้นหาสาเหตุของปัญหานี้มาเป็นเวลานาน แต่ทีมงานจาก NVIDIA และ Wipro ช่วยเราในการวิเคราะห์ปัญหานี้ เนื่องจากโมเดล โอเพ่นซอร์ส หลายๆ ตัวนั้น ข้อมูลที่นำมาพัฒนา พบว่ามี “ข้อมูลที่ไม่ใช่ภาษาอังกฤษ มีเพียงแค่ 5% ของ LLM และข้อมูลภาษาไทยนั้น น้อยกว่ามาก มันมีเพียงแค่ 0.5% ของ LLM” ในขณะที่ข้อมูลภาษา จีน มี 3% นี่คือเหตุผลที่ทำให้เกิดปัญหานี้ ดังนั้นวิธีที่เราหาทางแก้ไขคือ เราต้องทำเพิ่ม เรารวบรวมข้อมูล 15,000 ชุดข้อมูล เพิ่มเติม และทำการฝึกอบรมใหม่อีกครั้ง การทำเช่นนี้ช่วยในสองด้าน คือ ลดการ hallucination (หลอน) ในภาษาอื่นๆ และทำให้ข้อมูลภาษาไทยมีความถูกต้องและละเอียดมากขึ้น จากนั้นคุณซันก็แสดงผลลัพธ์หลังจากที่มีการปรับปรุงแล้ว และเชิญเพื่อนร่วมงานจาก Wipro ขึ้นบนเวทีพูดเพิ่มเติมเกี่ยวกับเรื่องนี้
รับชม VDO ตัวเต็ม

